Cornell University

Videos
Loading the player ...
- Offer Profile
- Our goal is to do breakthrough research on fundamental problems in robotics, in order to enable autonomous mobile manipulators to perform these and other challenging tasks. Our focus will be not only on exciting new research, but also on developing robust, widely applicable new tools and software that can be deployed and used by other researchers.
Product Portfolio
Projects

Make3D: Single Image Depth Perception
- Learning algorithms to predict depth and infer 3-d models, given just a single still image. Applications included creating immersive 3-d experience from users' photos, improving performance of stereovision, creating large-scale models from a few images, robot navigation, etc. Tens of thousands of users have converted their single photographs into 3D models.

Personal Robots: Learning Robot Manipulation
- Learning algorithms to predict robotic grasps, even for objects of types never seen before by the robot. Applied to tasks such as unloading items from a dishwasher, clearing up a cluttered table, opening new doors, etc.

Holistic Scene Understanding: Combining Models as Black-boxes
- Holistic scene understanding requires solving several tasks simultaneously, including object detection, scene categorization, labeling of meaningful regions, and 3-d reconstruction. We develop a learning method that couples these individual sub-tasks for improving performance in each of them.

Visual Navigation: Miniature Aerial Vehicles
- Use monocular depth perception and reinforcement learning techniques to drive a small rc-car at high speeds in unstructured environments. Also fly a indoor helicopters/quadrotors autonomously using a single onboard camera.

STAIR: Opening New Doors
- For a robot to practically deployed in home and office environments, they should be able to manipulate their environment to gain access to new spaces. We present learning algorithms to do so, thus making our robot the first one able to navigate anywhere in a new building by opening doors and elevators, even ones it has never seen before.
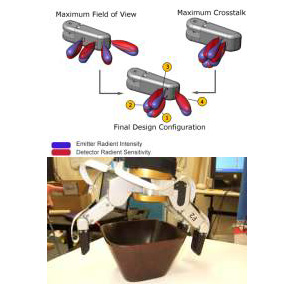
STAIR: Optical Proximity Sensors
- We propose novel optical proximity sensors for improving grasping. These sensors, mounted on fingertips, allow pre-touch pose estimation, and therefore allow for online grasp adjustments to an initial grasp point without the need for premature object contact or regrasping strategies.
Zunavision
- We developed algorithms to automatically modify videos by adding textures in them. Our algorithms perform robust tracking, occlusion inference, and color correction to make the texture look part of the original scene.

Visual Navigation: High speed obstacle avoidance
- Use monocular depth perception and reinforcement learning techniques to drive a small rc-car at high speeds in unstructured environments.

Make3D extension: Large Scale Models from Sparse View
- Create 3-d models of large environments, given only a small number of (possibly) non-overlapping images. This technique integrates Structure from Motion (SFM) techniques with Make3D's single image depth perception algorithms.

Improving Stereovision using monocular cues
- Stereovision is fundamentally limited by the baseline distance between the two cameras. I.e., the depth estimates tend to be inaccurate when the distances considered are large. We believe that monocular visual cues give largely orthogonal, and therefore complementary, types of information about depth. We propose a method to incorporate monocular cues to stereo (triangulation) cues to obtain significantly more accurate depth estimates than is possible with either alone.